
I were going to write an introduction about how important negative results can be. I didn’t. I assume you can figure out for yourself why that is and if not you got all the more reason to read this blog post. If you think it’s trivial why my result is negative, you definitely need to read the blog post.
The memory subsystem
I think most researchers would immediately think that reading kernel memory from an unprivileged process cannot work because “page tables”. That is what the Instruction Set Architecture or ISA says. But in order to understand why that was unsatisfactory to me we need to dig a bit deeper and I’ll start at the beginning.
When a software running on a Core requires memory it starts a so called
“load” command. The load command is then processed in multiple stages
until the data is found and returned or an error occurred. The Figure
below shows a simplified version of this sub system.
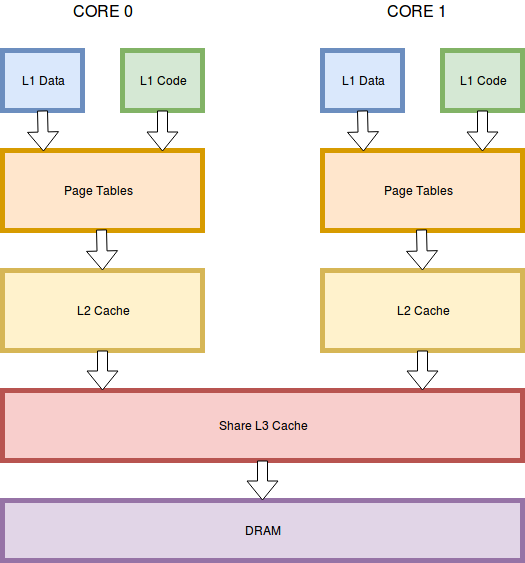
Software including operating system uses virtual addressing to start a load (which is what a memory read is called inside the CPU). The first stage of processing is the L1 cache. The L1 cache is split between a data and an instruction cache. The L1 Cache is a so called VIPT or Virtually Indexed, Physically Tagged cache. This means the data can be looked up by directly using the virtual address of the load request. This along with central position in the core makes the L1 incredibly fast. If the requested data was not found in the L1 cache the load must be passed down the cache hierarchy. This is the point where the page tables come into play. The page tables are used to translate the virtual address into a physical address. This is essentially how paging is enabled on x64. It is during this translation that privileges are checked. Once we have a physical address, the CPU can query the L2 cache and L3 cache in turn. Both are PITP caches (Physically Indexed, Physically Tagged) thus requiring the translation in the page tables before the lookup can be done. If no data was in the caches then the CPU will ask the memory controller to fetch the data in main memory. The latency of a data load in the L1 cache is around 5 clock cycles whereas a load from main memory is typically around 200 clock cycles. With the security check in the page tables and the L1 located before those we see already at this point that the because “page table” argument is too simple. That said – the intel manuals software developer’s manuals [2] states that the security settings is copied along the data into the L1 cache.
Speculative execution
In this and the next section I’ll outline the argumentation behind my theory, but only outline. For those a bit more interested it might be worth looking at my talk at HackPra from January [3] where I describe the pipeline in slightly more detail, though in a different context. Intel CPU’s are super scalar, pipelined CPU’s and they use speculative execution and that plays a big role in why I thought it may be possible read kernel memory from an unprivileged user mode process. A very simplified overview of the pipeline can be seen in figure below.
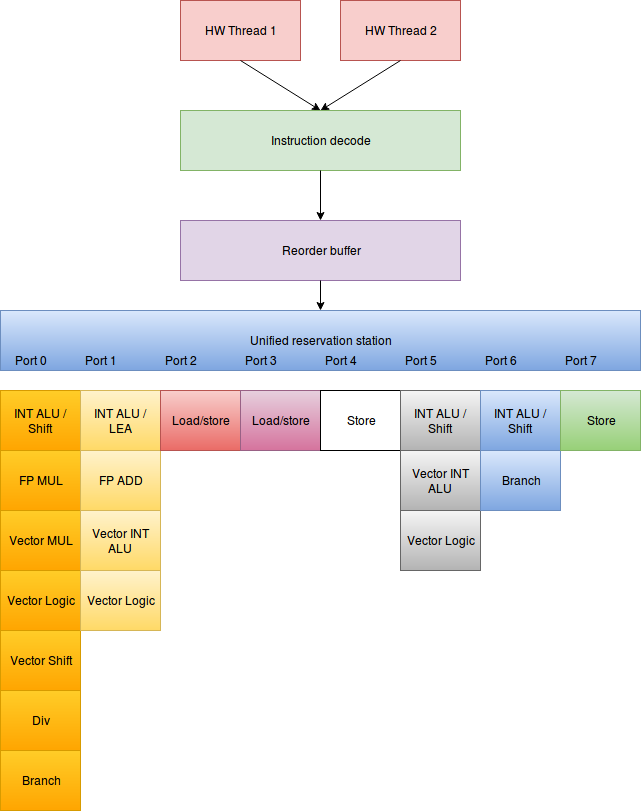
The pipeline starts with the instruction decoder. The instruction decoder reads bytes from memory, parse the buffer and output instructions. Then it decodes instructions into micro ops. Micro ops are the building blocks of instructions. It is useful to think of x86 CPU’s as a Complex Instruction Set Computer (CISC) with a Reduced Instruction Set Computer (RISC) backend. It’s not entirely true, but it’s a useful way to think about it. The micro ops (the reduced instructions) are queued into the reordering buffer. Here micro ops is kept it until all their dependencies have been resolved. Each cycle any micro ops with all dependencies resolved are scheduled on available execution units in first in ,first out order. With multiple specialized execution units many micro ops are executing at once and importantly due to dependencies and bottlenecks in execution units micro ops need not execute in the same order as the entered the reorder buffer. When a micro op is finished executing the result and exception status are added to the entry in the reorder buffer thus resolving dependencies of other micro ops. When all Micro ops belonging to a given instruction has been executed and have made it to the head of the reorder buffer queue they enter the retirement processing. Because the micro ops are at the head of the reorder buffer we can be sure that retirement is in the same order in which the micro ops were added to the queue. If an exception was flagged in the reorder buffer for a micro op being retired an interrupt is raised on the instruction to which the micro op belonged. Thus the interrupt is always raised on the instruction that caused even if the micro op that caused the interrupt was executed long before the entire instruction was done. A raised interrupt causes a flush of the pipeline, so that any micro op still in the reorder buffer is discarded and the instruction decoder reset. If no exception was thrown, the result is committed to the registers. This is essentially an implementation of Tomasulo’s algorithm [1] and allows multiple instructions to execute at the same time while maximizing resource use.
Abusing speculative execution
Imagine the following instruction executed in usermode
mov rax,[somekernelmodeaddress]
It will cause an interrupt when retired, but it’s not clear what happens between when the instruction is finished executing and the actual retirement. We know that once retired any information it may or may not have read is gone as it’ll never be committed to the architectural registers.. However, maybe we have a chance of seeing what was read if Intel relies perfectly on Tomasulo’s algorithm. Imagine the mov instruction sets the results in the reorder buffer as well as the flag that retirement should cause an interrupt and discard any data fetched. If this is the case we can execute additional code speculatively. Imagine the following code:
mov rax, [Somekerneladdress]
mov rbx, [someusermodeaddress]
If there are no dependencies both will execute simultaneous (there are two execution units for loads) and while the second will never get it’s result committed to the registers because it’ll be discarded when the firsts mov instruction causes an interrupt to be thrown. However, the second instruction will also execute speculatively and it may change the microarchitectural state of the CPU in a way that we can detect it. In this particular case the second mov instruction will load the
someusermodeaddress
into the cache hierarchy and we will be able to observe faster access time after structured exception handling took care of the exception. To make sure that the someusermodeaddress is not already in the cache hierarchy I can use the clflush instruction before starting the execution. Now only a single step is required for us to leak information about the kernel memory:
Mov rax, [somekerneladdress]
And rax, 1
Mov rbx,[rax+Someusermodeaddress]
If this is executed last two instructions are executed speculatively the address loaded differs depending on the value loaded from somekerneladdress and thus the address loaded into the cache may cause different cache lines to be loaded. This cache activity we can we can observe through a flush+reload cache attack.
The first problem we’re facing here is we must make sure the second and third instruction runs before the first one retires. We have a race condition we must win. How do we engineer that? We fill the reorder buffer with dependent instructions which use a different execution unit than the ones we need. Then we add the code listed above. The dependency forces the CPU to execute one micro op at a time of the filling instructions. Using an execution unit different than the one we used in the leaking code make sure that the CPU can speculatively execute these while working on the fill pattern.
The straight forward fill pattern I use is 300 add reg64, imm. I choose add rax, 0x141. I chose this because we have two execution units that are able to execute this instruction (Integer alus) and since they must execute sequentially one of these units will always be available to my leakage code (provided that another hardware thread in the same core isn’t mixing things up).
Since my kernel read mov instruction and my leaking mov instruction
must run sequentially and that the data fetched by the leaking
instruction cannot be in the cache the total execution time would be
around 400 CLK’s if not the kernel address isn’t cached. This is a
pretty steep cost given that an add rax, 0x141 cost around 3 CLK’s. For
this reason, I see to it that the kernel address I’m accessing is loaded
into the cache hierarchy. I use two different methods to ensure that.
First, I call a syscall that touches this memory. Second, I use the
prefetcht0 instruction to improve my odds of having the address loaded
in L1. Gruss et al [4] concluded that prefetch instructions may load the
cache despite of not having access rights. Further they showed that
it’s possible for the page table traverse to abort and that would surely
mean that I’m not getting a result. But having the data already in L1
will avoid this traverse.
All said and done there are a few assumptions I made about Intels implementation of Tomasulo’s algorithm:
1) Speculative execution continues despite interrupt flag
2) I can win the race condition between speculative execution and retirement
3) I can load caches during speculative execution
4) Data is provided despite interrupt flag
Evaluation
I ran the following tests on my i3-5005u Broadwell CPU.
I found no way I could separately test assumption 1,2 and 3. So I wrote up the code I outlined above and instead of code above I used the following code:
Mov rdi, [rdi]; where rdi is somekernelmodeaddress
mov rdi, [rdi + rcx+0]; where rcx is the Someusermodeaddress
Then I timed accessing the Someusermodeaddress after an exception handler dealt with the resulting exception. I did 1000 runs and sorted out the 10 slowest out. First I did a run with the 2nd line above present with the value at the kernel mode address 0. I then did a second run with the second line commented out. This allows me test if I have a side channel inside the speculative execution. The results is summarized in the below histogram (mean and variance respectively: mean= 71.22 std = 3.31; mean= 286.17 std = 53.22). So obviously I have a statistic significant covert channel inside the speculative execution.
In a second step I made sure that the kernel address I was trying to
read had the value 4096. Now if I’m actually reading kernelmode
data the second line will fetch a cache line in the next page. Thus I
would expect a slow access to Someusermodeaddress. As the speculative
fetch should access a cache line exactly one page further. I selected
the offset 4096 to avoid effects due to hardware prefetchers I could’ve
added the size of a cache line. Fortunately I did not get a slow read
suggesting that Intel null’s the result when the access is not allowed. I
double checked by accessing the cache line I wanted to access and
indeed that address was not loaded into the cache either. Consequently
it seems likely that intel do process the illegal reading of kernel mode
memory, but do not copy the result into the reorder buffer. So at this
point my experiment is failed and thus the negative result. Being really
curious I added an add rdi,4096 instruction after the first line in the
test code and could verify that this code was indeed executed
speculatively and the result was side channeled out.
Pandoras box
While I did set out to read kernel mode without privileges and that produced a negative result, I do feel like I opened a Pandora’s box. The thing is there was two positive results in my tests. The first is that Intel’s implementation of Tomasulo’s algorithm is not side channel safe. Consequently we have access to results of speculative execution despite the results never being committed. Secondly, my results demonstrate that speculative execution does indeed continue despite violations of the isolation between kernel mode and user mode.
This is truly bad news for the security. First it gives microarchitecture side channel attacks additional leverage – we can deduct not only information from is actually executed but also from what is speculatively executed. It also seems likely that we can influence what is speculative executed and what is not through influencing caches like the BTB see Dmitry Evtyushkin and Dmitry Ponomarev [5] for instance.It thus add another possibility to increase the expressiveness of microarchitecture side channel attacks and thus potentially allow an attacker even more leverage through the CPU. This of cause makes writing constant time code even more complex and thus it is definitely bad news.
Also it draws into doubt mitigations that rely on retirement of instructions. I cannot say I know how far that stretches, but my immediate guess would be that vmexit’s is handled on instruction retirement. Further we see that speculative execution does not consistently abide by isolation mechanism, thus it’s a haunting question what we can actually do with speculative execution.
Literature
[1] Intel® 64 and IA-32 Architectures Software Developer Manuals. Intel. https://software.intel.com/en-us/articles/intel-sdm
[2] Tomasulo, Robert M. (Jan 1967). “An Efficient Algorithm for Exploiting Multiple Arithmetic Units”. IBM Journal of Research and Development. IBM. 11 (1): 25–33. ISSN 0018-8646. doi:10.1147/rd.111.0025.
[3] Fogh, Anders. “Covert shotgun: Automatically finding covert channels in SMT”
https://www.youtube.com/watch?v=oVmPQCT5VkY.
[4] Gruss, Daniel, et al. “Prefetch side-channel attacks: Bypassing SMAP and kernel ASLR.”
Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2016.
[5] Evtyushkin D, Ponomarev D, Abu-Ghazaleh N. Jump Over ASLR: Attacking Branch Predictors to Bypass ASLR. InProceedings of 49th International Symposium on Microarchitecture (MICRO) 2016.

